The New News Service
Here we will explain how did we create a new service for our news pages which are one of the centre of attraction of the visitors who are coming to our website. And we did it so along with some change in the functionality and look and feel of the pages and that too with some change in the technical architecture as well
Architecture Diagram

Components Of News Service:-
1) Mysql
2) Redis
3) CDC
4) Kafka
5) Cloudfront CDN
Let us explore the different components of our news backend service
1) Mysql
MySQL is a Relational Database Management System (RDBMS) that is available as free, open-source software under the GNU General Public License. It is a database management system that is fast, scalable, and simple to use. MYSQL is compatible with a variety of operating systems, including Windows, Linux, and macOS. MySQL is a Structured Query Language (SQL) that allows you to manipulate, manage, and extract data using various Queries. It is supported by Oracle Company.
Features:-
- Relational Database Management System (RDBMS): MySQL is a relational database management system. The SQL queries are used to view and control the table’s records in this database language.
- Easy to use: MySQL is a simple database to work with. We just need to learn the fundamentals of SQL. Only a few simple SQL statements are needed to construct and interact with MySQL.
- It is secure: MySQL has a strong data protection layer in place to keep confidential data safe from intruders. In addition, MySQL encrypts passwords.
- Client/ Server Architecture: A client/server architecture is followed by MySQL. A database server (MySQL) and an unlimited number of clients (application programs) connect with the server, allowing them to query data, save changes, and so on.
- It is scalable: MySQL is modular since it allows multi-threading. It can deal with virtually any amount of data, up to 50 million rows or more. Approximately 4 GB is the default file size max. However, we can theoretically increase this number to 8 TB of data.
- High Flexibility: MySQL is very versatile since it supports a wide range of embedded applications.
- Allows roll-back: MySQL supports rolled back, committed, and crash recovery transactions.
- Memory efficiency: Its performance is high due to the fact that memory leakage is minimal.
- High Performance: Because of its special storage engine architecture, MySQL is quicker, more efficient, and less expensive. It achieves very good performance outcomes as compared to other databases without sacrificing any of the software’s critical features. Because of the different cache memory, it has fast-loading utilities.
- High Productivity: Triggers, stored procedures, and views are all used in MySQL to help developers be more productive.
Note:- We have used triggers in our service
- Partitioning: This feature enhances efficiency and allows for quick management of large databases.
- utf8mb4:- A UTF-8 encoding of the Unicode character set using one to four bytes per character.We have used utf8mb4 in our mysql tables for saving the news data for Hindi News.The
utf8mb4character set is useful because nowadays we need support for storing not only language characters but also symbols, newly introduced emojis, and so on
2) Redis
Redis is an open-source, in-memory data structure store, used as a distributed, in-memory key-value database, cache, and message broker, with optional durability. Redis supports different kinds of abstract data structures, such as strings, lists, maps, sets, sorted sets, HyperLogLogs, bitmaps, streams, and spatial indexes.
Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Some of the use cases of Redis are:
- Caching
- Messaging and Queue
- Session Store
- Machine Learning
Caching: Redis is perfect for implementing a high in-memory cache to decrease data access latency and increase throughput. They can respond in milliseconds which makes it pretty fast and it also enables you to easily scale for higher loads without spending a huge amount of money for just the backend. Database query results caching, persistent session caching, web page caching, and caching of frequently used objects such as images, files, and metadata are all popular examples of caching with Redis.
Messaging and Queue: Redis also supports Pub/Sub (Publish and Subscribe) with pattern matching and a variety of data structures.
Session Store: For internet-scale applications, Redis is the best choice as it supports in-memory. It provides sub-millisecond latency, scale, and resiliency required to manage session data like session state, credentials, and more.
Machine Learning: As we know, Machine Learning models can be a slow and time-consuming process to load some data as inputs and process it to produce outputs. This process can be handled by Redis and the application performance can be increased significantly.
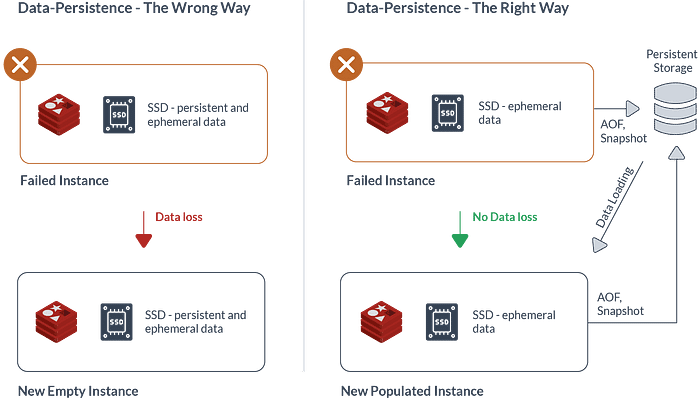
Advantages Of using Redis
Redis is great for delivering results faster and managing data that is to store and retrieve it. Some merits of Redis are:
- Faster Database responses: They store data in RAM, rather than on an HDD (Hard Disk Drive) or SSD (Solid State Drive).
- Has Control over Lifetime of a Data: Redis supports the Time to Live (TTL) feature where if the keys are set in TTL mode with the duration time to live, data will expire after this time elapses.
- Key-Based Access: Redis is based on a key-value model. Key-Based access allows for extremely efficient access times. We can access the data using Redis GET and SET semantics. They are very fast though, they can perform around 110, 000 SETs per second and around 81, 000 GETs per second.
Our application is heavily relying on the Redis for caching the API responses so that once the data is accessed from the database in saved into the in memory redis cache and the subsequent requests are then served from the cache to return the required response to the clients which increases our API speed and hence the page speed.
3) CDC(Change Data Capture)
Change Data Capture (CDC) captures incremental changes in the original database so that they can be propagated to other databases or applications in near real-time.
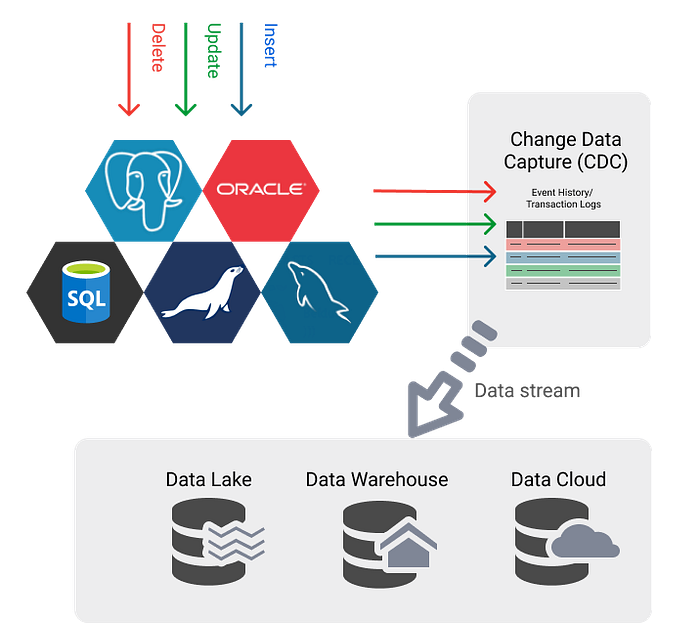
Change Data Capture (CDC) captures incremental changes to data and data structures (also called schemas) from the source database. So that changes can be propagated to other databases or applications in near real-time. In this way, CDC provides efficient low-latency data transfers to data warehouses, where the information is then transformed and delivered to analytics applications.
Replication of time-sensitive information is also an important aspect when migrating to the cloud when data is constantly changing, and it is impossible to interrupt connections to online databases.
Change Data Capture has three fundamental advantages over batch replication:
- CDC reduces the cost of transferring data over the network by sending only incremental changes.
- CDC helps you make faster, more accurate decisions based on the most recent, up-to-date data. For example, CDC propagates transactions directly to analytics applications.
- CDC minimizes disruption to production workloads.
We are using the transactional log based CDC for our service
Transactional Log CDC
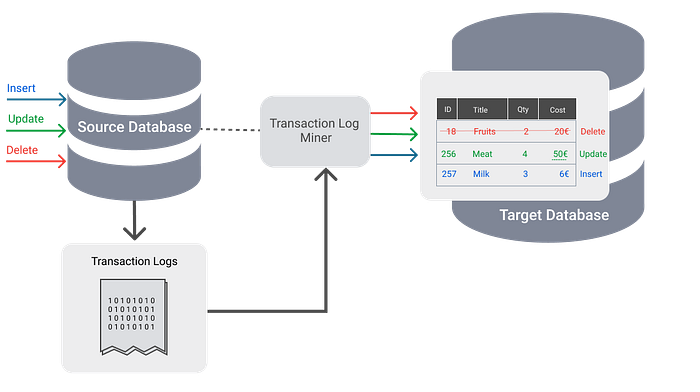
Databases use transaction logs primarily for backup and recovery purposes. But they can also be used to replicate changes to a target database or a target data lake.
In a “transaction log” based CDC system, there is no persistent storage of data stream. Kafka can be used to capture and push changes to a target database.
We are using Maxwell connector here for our CDC purpose which is very easy to use and setup along with it is Devops friendly as well. We can learn more about the Maxwell connector from here
Advantages of transactional log based CDC:-
- Minimal impact on production database system — no additional queries are required for each transaction.
- There is no need to change the schemas of the production database system or add additional tables.
- We can create an array of separate consumers applications which can be scaled independently and can perform various tasks independently.
4) Kafka : Our Queuing system
Kafka is a Distributed Streaming Platform or a Distributed Commit Log
Distributed
Kafka works as a cluster of one or more nodes that can live in different Datacenters, we can distribute data/ load across different nodes in the Kafka Cluster, and it is inherently scalable, available, and fault-tolerant.
Streaming Platform
Kafka stores data as a stream of continuous records which can be processed in different methods.
Commit Log
This one is my favorite. When you push data to Kafka it takes and appends them to a stream of records, like appending logs in a log file or if you’re from a Database background like the WAL. This stream of data can be “Replayed” or read from any point in time.This is very useful in case of replaying the data from the point your service encountered an error.
Is Kafka a message queue:-
It certainly can act as a message queue, but it’s not limited to that. It can act as a FIFO queue, as a Pub/ Sub messaging system, a real-time streaming platform. And because of the durable storage capability of Kafka, it can even be used as a Database.
Kafka is commonly used for real-time streaming data pipelines, i.e. to transfer data between systems, building systems that transform continuously flowing data, and building event-driven systems.
Here we are all using the kafka for streaming the Mysql CDC events to the Kafka topics. We have created a separate consumer application to consume the events from Kafka topic so that we can update the redis cache with the updated information which we received from the MYSQL along with Cloudfront invalidations.
5) Cloudfront CDN
Before understanding the Cloudfront, let us understand the CDN first
CDN(Content Delivery Network):- CDN stands for Content Delivery Network. It is a very large distribution of caching servers that are located around the world. It contains content that are stored in your origin servers and routes the viewers to the best location so that they can view the content that is stored in the cache. The content can be static (content that does not change)or dynamic (content that does change) in nature. CDN adds to the scalability and performance factor of applications.
CloudFront:- It is Amazon’s global content delivery network with massive capacity and scale. It is optimized for performance and scalability. Security features are also built in and you can configure them for optimal service. The user is in control of the service and can make changes on the fly. It includes real time reporting so that you can monitor the performance and make changes to the application or the way the CDN interfaces with your application. It has been optimized for static and dynamic objects and video delivery.
When a user requests objects on your website or application, the DNS routes the request to the nearest CloudFront edge location, which can best serve the user’s request in terms of latency. In the edge location, CloudFront will check the cache to see if the content being requested is there in the cache and returns it to the user. If the content is not there in the cache, then CloudFront will forward the request to the applicable origin server. The origin server will send the corresponding file to the CloudFront edge location which will be forwarded by CloudFront to the user and also stored in the cache in case someone else tries to request that file.
So, here we are using Cloudfront in our application to reduce the latency of the content which we are receiving at the user's end which will help us increase the speed of the page.
News Page Invalidations
When a user requests content from a website, CloudFront checks if the content is available in its cache. If the content is available in the cache, CloudFront delivers the content to the user from its cache. This speeds up the delivery of the content and reduces the load on the website’s servers.
However, if the content has changed on the website, the cached content in CloudFront will be outdated. To ensure that users receive the latest content, the cached content in CloudFront needs to be invalidated. This means that the cached content is removed from the CDN, and the next time a user requests the content, it is fetched from the website’s servers.
Whenever any content is changed in our primary database which is Mysql,it is being streamed to Kafka topic via CDC(Maxwell connector in our case) and our consumer listens to the event and invalidates the cache for the particular content or url so that the user can see the fresh content every time the content gets updated.
We have tried to build a new service for our news pages in a way which is very reliable,scalable and fault tolerant. All these mentioned will ensure that our application runs in a smooth way with minimal latency and zero downtime providing an enriching experience to our end users

Comments ()